
Nvidia Envy: understanding the GPU gold rush
In 2023, thousands of companies and countries begged Nvidia to purchase more GPUs. Can the exponential demand endure?

With internet, SaaS, and mobile tailwinds in the rear-view mirror, the tech industry has become cash-rich but growth-poor. 2023 marked an unexpected return to dot-com era growth across ChatGPT, Midjourney, Character, and Copilot. Even more viral was the growth in the number of tech companies wanting a part of the newfound tailwinds.
Multiple factors drove the launch success of the 2022 AI products: magical user experiences, large-scale data acquisition and refinement, engineering team quality, viral press distribution, and scaled compute. Most of those advantages are hard, if not impossible, to replicate.
For the thousands of cash-rich and growth-poor tech companies that were caught off guard, the easiest thing to copy was the large-scale GPU purchasing, and figure out the rest later. This made Nvidia the AI kingmaker, as they could determine who was worthy of purchasing their frontier H100 GPUs at scale. Dozens of companies cropped up to resell GPUs and profit off of the ensuing shortage.
Will the exponential growth of Nvidia demand continue to outpace supply? Answering the trillion dollar shortage question is challenging – with FUD and propaganda driving the GPU conversation, it is hard to see through the noise to develop an intuition for the supply and demand dynamics at play.
A few factors amplified the GPU shortage, and understanding them should help us understand how the 2020s will unfold:
The incentives to undermine Nvidia’s GPU monopoly have grown to 4-comma proportions. With several players each buying hundreds of millions (some purchasing billions) of frontier Nvidia chips at software-level margins, the incentives are stronger than ever to undermine their pricing power.
There is a fat long tail of GPU purchasers. The enormous backlog of GPU demand is more than just big tech. In fact, the core hyperscalers (Google, Microsoft, Amazon) only constitute about half of Nvidia H100 sales. There is a long tail ranging from seed-stage venture-backed startups to nation-states.
There are many FOMO-driven GPU cluster builds with unclear ROI. The long tail of demand can’t avoid the Nvidia tax by building GPUs themselves, but its longer-term demand is also much shakier than stable big tech companies. The number of foundation models with product-market fit can be measured on one hand, but the number of GPU purchasers is in the thousands.
Nvidia operates in boom-bust cycles. Big tech companies are historical anomalies in terms of their steady compounding. Unlike the other big tech companies, Nvidia has a far more volatile growth story.
It is impossible to precisely predict the future of GPU supply and demand, but I hope to bring tech-savvy GPU-laypeople up to speed on the Nvidia craze, LLM training mega-runs, and the resulting shortage.
Why GPU scaling matters
GPUs, or graphical processing units, were first developed in the 1970s to perform graphical operations very quickly for video games. They are the closest thing we have to an antidote to the breakdown of Moore’s Law.
While CPUs can perform any workload, GPUs are optimized at the hardware-level for parallel operations. To oversimplify somewhat, that means you can perform thousands of operations at the same time, instead of waiting for operation A to complete before starting B. As it turned out, matrix multiplication is useful for more than rendering polygons on a screen – it is also used in training and running inference on neural networks.
Moore’s Law enabled the technological frontier for the past half-century. Unfortunately, the law broke down in the 2010s for CPUs. While the compute per dollar isn’t scaling quite as quickly as Moore’s Law, the absolute compute performance gains are still quite impressive:

It’s hard to know whether there’s some efficiency frontier at which we should stop investing in incremental compute performance. Laying internet fiber, for example, became a lot less profitable in the last decade.
But I’m consistently surprised by the emergent phenomenon from pushing the compute frontier. In 2010, a model like GPT-4 was not technically feasible – the largest supercomputer had computing power equivalent to ~1,000 H100s. If each order of magnitude increase in data and compute drives a jump in LLM IQ points, what might happen at the next order of magnitude?
Most exponentials in technology are really just S-curves – internet adoption, ad dollars, SaaS market sizes – but compute may be one of the few that endures as a true exponential, more similar to GDP or energy consumption (though even energy’s exponential growth eventually stalled). In 2043, it seems clear that the 2023 market for compute will look small in the rear-view mirror.
When I was an undergrad at Stanford, few people paid attention to electrical engineering – it was perceived as a solved problem, and instead everyone moved up the stack to software. But ignoring the hardware layer was a mistake – we have a duty to understand computing hardware as one of the closest things to an enduring exponential that we have.
The Nvidia empire
Many big tech players have plans to wean themselves off of Nvidia, but If you want to compete at the frontier of large-scale foundation models today, Nvidia is the only practical choice.
My friend Ben Gilbert did a great series on Nvidia’s corporate history here, but in short: the company was founded in 1993 to bring 3D graphics to gaming, and released its first GPU in 1999. They invented CUDA in 2006, which allows for parallel processing across multiple GPUs, setting the stage for the development of GPU clusters used to train larger workloads.
They have a monopoly on supercomputers, powering 74% of the top 500 supercomputers and nearly all large-scale AI training clusters. Startups pitch their relationship with the company as a core differentiator (e.g. being first in line to buy chips). While Nvidia started as a consumer GPU company, the heart of Nvidia’s banner 2023 is the data center business.
Data Center business
Nvidia’s data center business sells GPUs for AI + high-performance computing workloads. It hit a $17b revenue run rate (56% of revenue) in Q1, and more than doubled (!) to a $41b run rate in Q2 (76% of revenue). Wall Street analysts are anticipating another banner year in 2024 (FY25), with $60-100b in data center revenue.

Nvidia lineup overview
The devices below are Nvidia’s high-performance computing line, intended for large-scale workloads and often assembled in clusters (many GPUs networked together into one supercomputer):
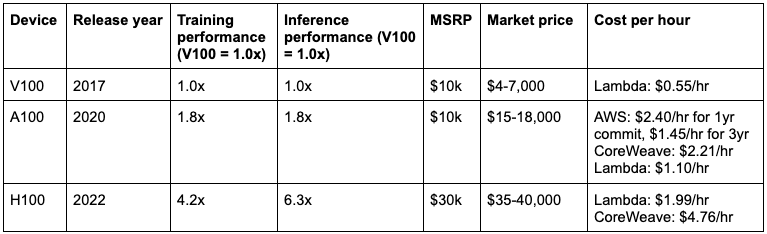
As of Q2, Nvidia’s data center revenue is roughly half A100s and half H100s, but shifting rapidly to H100s as A100 production winds down. For training large-scale LLMs (think GPT-4 level), H100s are the best performers in terms of both speed (time to train) and cost (i.e. flops per dollar). For smaller language models and image models (think GPT-3 or Stable Diffusion), A100s (and even the cheaper A10s) are a cost-effective GPU for both training and inference.
To train a model to GPT-3 level performance, the compute required is relatively low – this explains why there were so many demos within just a few months of ChatGPT’s launch that approximated GPT-3 performance. There are dozens of clusters with 1,000+ A100s.
For GPT-4 level performance, the bar is significantly higher. Only a handful of companies including Microsoft, Amazon, Google, and Facebook have access to tens of thousands of frontier GPUs in a single cluster, not to mention the hurdles around high-quality data acquisition and training techniques. Scaling data acquisition and compute is hard and expensive – this is why nobody has surpassed general GPT-4 performance, even 8 months after launch.
This chart should give you a sense for the scale of compute required to train various models:

The GPU demand curve: growth or glut?
In the summer of 2023, it became clear that there was a run on Nvidia GPUs. As of summer 2023, H100s were sold out until Q1 2024.
There is an unstoppable force of GPU efficiency gains and supply chain unlocks against an immovable wall of $100m+ LLM training runs. It is impossible to know when the GPU shortage ends, but we can triangulate the duration of the shortage by better understanding the current demand dynamics and where they’re heading.
Present day: who exactly is buying GPUs?
There are a handful of downstream players buying the Nvidia GPUs: the hyperscalers (Google, Microsoft, Amazon), the large foundation models, and a surprisingly large number of mid-sized AI teams at startups and enterprises.
The big tech companies that need large-scale GPU clusters for internal purposes are best positioned to train their own LLMs, as they already have the ML expertise and internal demand for large H100 clusters. The core hyperscalers (AWS, Azure, GCP) are each spending $20b+ in capex per year, a figure still scaling by 25%+ annually. The capex race is causing smaller cloud providers to play catchup: Oracle has doubled its capex twice, from $2.1b in 2021 to $4.5b in 2022 to $8.7b in 2023.
The hyperscalers don’t report exact GPU spend, but industry insiders estimate that each player spends ~20-35% of data center capex on GPU build-outs (GPU purchase orders, surrounding data centers / power supplies, etc.), with Microsoft being the most aggressive. The percentage of revenue that GPUs are driving for the cloud services is still small, but growing quickly. Rough estimates are in the 5-15% range, with Azure on the high end.
The hyperscalers each have 150k+ A100s, with individual clusters up to ~25k units. But they’ve largely paused on A100 purchases in favor of the next-gen H100. The largest H100 clusters are 20-30,000 units (Microsoft, Meta, Amazon, and Google), and are used for a combination of internal products, external rental via Azure / AWS / GCP, and their respective AI partners (OpenAI, Inflection, Anthropic). There’s a mid-tail of purchasers with a few thousand A100s and H100s, like Stability, Tesla, Lambda Labs, Hugging Face, Aleph Alpha, and Andromeda.
H100s serve the LLM training use case uniquely well given their high bandwidth and memory. But H100 performance is overkill for seemingly adjacent applications like stable diffusion (image generation models), smaller model training (even GPT-3 scale), and LLM inference. It is unclear whether the other use cases like stable diffusion and lagging-edge LLM inference will scale up their memory and bandwidth needs into requiring H100s.
Medium-term outlook: expect volatility
Nvidia plans to ramp its production to 2m+ H100s next year (some say as high as 3-4 million). Can the demand match it? To make an educated guess on what 2024 looks like, we can look at the demand across the two groups of purchasers: the hyperscalers and the long tail.
Hyperscalers
The hyperscalers are receiving tens of thousands of H100s each this year – anywhere from 20k on the low end, to 100k+ on the high end. Microsoft is one of the largest purchasers of H100s (if not the largest), and while Google wants to support its internal TPU efforts, is also ramping H100 purchases to support their 26,000 H100 A3 cluster.
In their Q2 earnings report, Nvidia disclosed that one cloud service provider accounted for 29% of quarterly data center revenue, totaling a $3.9b purchase (!) in the first 6 months of 2023, equating to ~130k H100s. I suspect this is Microsoft purchasing ahead of demand to support upcoming Office Copilot launches, OpenAI compute, and Azure services. They even reserved excess capacity via CoreWeave and Oracle – a great move to flex up GPU capacity if Office Copilot takes off, while minimizing risk of overspending on GPU capex if demand comes in light.
Hyperscalers constitute roughly 50% of all H100 demand today. And of those hyperscaler purchases, a large fraction is to support upcoming product launches like Office Copilot and Google Gemini. The attach rate for big tech’s LLM-enabled products will be the earliest indicator for what the medium-term Nvidia H100 demand looks like.
This set of products will undoubtedly see immense adoption in absolute dollar terms, but I suspect won’t be enough to justify a much larger H100 investment until these companies work out the product kinks, vertical-specific use cases, and sales motions.
As one example: GitHub Copilot is one of the fastest-growing AI products at $100m+ in ARR after a year, but relatively small compared to 1) all VSCode users (14m users implies sub-5% Copilot penetration), and 2) Microsoft’s overall AI investment in the tens of billions. For the GPU investment to pay off, they’ll need the broader Office Copilot offering to increase Office’s $50b revenue base by at least 10%, or $5b+ in revenue.
The long tail
If big tech is only part of the H100 demand story, who else is buying in volume? Outside of the hyperscalers, there is a gigantic long tail of buyers. Even at the big tech companies, a large portion of the H100s (~30-50%) will be utilized by their customers as part of the cloud offerings (AWS, GCP, Azure). This means that ~⅔ of total H100 utilization is the long tail.
Seemingly everyone ordered anywhere from a few hundred to a few thousand H100s – Cloudflare, Palantir, HP, Voltage Park, Cohere, and even nation-states like Saudi Arabia and the UAE. And those that haven’t bought chips are spending aggressively on reserving GPU-time from the GPU landlords.
For those that are training or fine-tuning models on their own GPUs, cluster utilization is often low. ChatGPT was anomalous in that the product-market fit came essentially as soon as the product was launched. This means that internal demand for inference-focused GPUs ramped up quickly, keeping GPU utilization high.
Most companies training foundation models won’t achieve product-market fit as quickly – either the model isn’t good enough, or the product isn’t good enough, or the go-to-market isn’t good enough. This could create an internal GPU demand curve could look very roughly like this:

If you multiply that across the entire industry, you could see a large temporary gap in GPU demand for the long tail. The medium-term question is whether the inference ramp-up of the winners happens before the low-ROI training runs die out.
Cyclicality of demand
One challenge in forecasting GPU demand is that each release is highly cyclical and front-weighted – just 3 years after the A100 launch in 2020, for example, Nvidia is ramping down production.
While Nvidia’s GPUs were primarily used for gaming through the early 2010s, the 2017 and 2020-era crypto booms massively accelerated their growth. And with nearly perfect timing, the AI boom kicked in right as crypto started cooling off:

The AI-driven demand should be far more durable than the crypto mining boosts, given the higher quality of the customer base and ROI that should flow directly into productivity benefits. But because GPUs are typically bought as irregular capital expenditures, the semiconductor industry has historically been a boom-and-bust business.
Despite seemingly perfect exponential growth in the rearview mirror, Nvidia’s unpredictable growth spurts create one of the most volatile revenue bases of the big tech companies:

Geographical scaling
20% of the demand is Chinese tech: given bans on high-performance GPU sales to China, many Chinese tech companies have been stockpiling an unusually high number of chips anticipating increased US export controls.
Chinese tech giants Baidu, ByteDance, Tencent, and Alibaba are spending $1b on chips (primarily A800s, a watered-down A100 per US-CN AI regulations) that will be delivered this year, and $4b on chips for 2024. With China at 20% of Nvidia’s revenue (and potentially higher if you consider the potential pass-through from Middle Eastern GPU purchases), increased export controls could create a meaningful headwind over the medium term.
Long-term outlook: does the ROI come?
Over a multi-decade time horizon, we’ll certainly scale global compute exponentially, so it is easy to make the long-term bull case on GPUs. Trying to predict 5-year demand is much harder. Understanding the key levers – model size, model quantity, model ROI, and inference – will help us make some guesses as to what direction the aggregate demand is heading.
Scaling the number and size of models
To forecast long-term training GPU demand, you need some perspective on 1) how big foundation models get, and 2) how many models will win.
On #1, if large-scale models like OpenAI, Bard, and Anthropic determine that scaling laws hold (that is, more compute → more intelligence), they could easily increase their frontier GPU demand by an order of magnitude in the coming years, and others would follow suit. On the flip side, many B2B AI products are minimizing underlying model sizes by fine-tuning domain-specific, constrained-output models – these are far less GPU intensive.
Regarding #2 on the consumer side, early indicators suggest there will be a power law distribution of model success. Of the top 50 consumer AI apps, ChatGPT is 60% of all web traffic (an imperfect measure, to be sure), and running on less than 5% of global H100 capacity:

Regarding #2 on the enterprise side, the API market is similarly lopsided, with a short list of runners-up like Llama-2, Claude, and Cohere. More infra providers will come online, but like cloud infrastructure providers in the 2010s, you only need a small handful of providers to cover 80% of the market needs.
This leads to a puzzling scenario: seemingly infinite GPU demand from thousands of tech companies, but only a few players seeing ROI. Industry estimates suggest that the Microsoft cluster for OpenAI’s GPT-4 was around 20-25k H100s, and there are 3+ million H100s coming online in the next 18 months. How many GPT-4 level models do we really need?
I understand that there’s a believable optimistic case – OpenAI could scale GPT-5 to train on much larger clusters, others would follow suit, and there could be tens of thousands of companies fine-tuning models. But the hyperscalers will likely need some time to digest their large H100 orders from 2023. Demand into the millions of H100s per year is dependent on a many-models world that I’m not sure is sustainable.
The ROI gap
By the end of 2024, Nvidia will have sold $100-120b in H100s. The key AI-powered applications (OpenAI, Midjourney, Copilot, and a few others) sum to less than $5b in revenue today. When accounting for the ancillary costs like energy and labor, this means that AI application revenue needs to grow at least 20-50x to justify the capital investment, via home-run startups and $10b+ smash hit LLM products across the big tech players. As David Cahn put it clearly: there is a $100b+ hole to be filled for each year of capex at current spend levels.
The first cohort of ChatGPT reactionaries should demonstrate their ROI over the next few quarters. The returns will be highly variable – while the compute spend is surprisingly widely distributed, the revenue and user growth is not:

The early results from the second wave of fast-follower foundation models are already not showing the same ROI as the first – in spite of dozens of foundation model product launches in 2023, none have outshined the first crop of products that launched in 2022. Without the novelty X-factor and free global PR that made the early winners work, I suspect that the vast majority of the reactionary foundation models will be in for a world of hurt.
Inference
Today, there are relatively few scaled AI applications – it takes time to build out interaction paradigms that are sufficiently accurate, reliable, and trusted. Even Microsoft’s relatively productionized GPU clusters are running primarily training workloads, with the minority on inference. Most big tech companies estimate that by 2025, their GPU workloads will flip to 30% training and 70% inference (of course, this could underestimate the training ramp-up from some of the major AI labs).
The demand for inference could dramatically exceed the available GPU supply on short notice, though. For example, Midjourney has ~10,000+ GPUs for inference, and ~1.5 million active users. If they reach 30 million active users at the same efficiency, they could single-handedly demand hundreds of thousands of GPUs. There are dozens of software companies with millions of users that are releasing LLM-powered products in the coming months. If a fraction of those cross-sell effectively, inference demand could easily soak up all available GPU capacity.
The GPU market has been heavily weighted towards training, where Nvidia shines, and not inference. For inference, which is an unusually big expense item relative to the “zero marginal cost” world of 2010s software, cost structure really matters.
The H100 is often overkill for inference-style workloads, given the GPU is idle for the time spent transmitting to the CPU, which is why Nvidia created the lower-end L4 and A10 devices. Inference is where other companies have a fighting chance against Nvidia: Google’s v5e TPU is already a popular inference option (but requires GCP lock-in), and AMD’s MI300 is already proving it is well-suited for inference as a CPU-GPU hybrid.
As inference ramps up where price performance dominates, AMD has a shot at becoming a key provider by undercutting Nvidia. AMD’s AI revenue base is small relative to Nvidia, but enough to be a credible alternative, with $2b in AI chip sales anticipated for 2024. This should ensure they are a must-evaluate in any large-scale GPU purchase. Given the product requirements differ for training and inference, we could see increased GPU market segmentation.
The supply side: Nvidia’s monopoly on GPUs
Nvidia is tripling its output of H100s to ship 2m+ units in 2024, bottlenecked primarily by TSMC. You can read a detailed analysis of the upstream component supply chain bottlenecks from Dylan Patel’s SemiAnalysis here.
Nvidia has monopoly market share over GPU supply (80%+ of revenue), which was a somewhat reasonable equilibrium when there was less attention on the market. If you’re spending $10 million, or even $50 million, per year of your compute bill on GPUs, and it’s a tiny fraction of your cost structure, it’s easy to outsource to Nvidia.
But if you’re spending $500m/yr on GPUs and they become a material part of your variable cost structure, the calculus is different. Now, the set of companies with $100m+ in GPU spend that are hungry for margin expansion is much larger. The incentives to break Nvidia’s market dominance have grown tenfold in the past year.
This means that Nvidia’s customer base is riskier than meets the eye: the long tail of customers may not prove any ROI from their nascent foundation model GPU clusters, but the largest customers are trying very hard to undermine their Nvidia dependence.
To borrow a phrase from Bezos, “your margin is my opportunity” – and Nvidia has created tens of billions in opportunity this year.
Hyperscalers
Google started TPU development in 2015, as one of the largest consumers of accelerated computing at the time (search, ads, translate). TPU performance isn’t as good as Nvidia’s H100 series (they don’t even try comparing it), but it doesn’t need to be – they get a massive cost reduction from internal chip development. Nvidia sells the H100 unit for $30,000, and their COGS are ~$3,320, creating software-level gross margins, far higher than any other link of the GPU supply chain.
Microsoft is working on its own AI chip with AMD’s help, called the Athena project, which The Information reported on in April 2023. There are 300 people staffed on the project, which started in 2019. There are some rumors that Microsoft will prioritize support for AMD’s upcoming MI300 chip.
Even Amazon is ramping up their own chip development efforts, though fighting from behind. They still seem to be figuring out their AI strategy: they’re developing their own chips, trying to train their own foundation models, investing in Anthropic, and hosting Llama-2 instances. Typically, a higher number of strategies corresponds to a lower level of conviction.
AMD
Players like AMD are trying their best to catch up, or at least drive down the A100/H100 monopoly pricing power. Their frontier MI300 chip won’t beat the H100, but in the words of an industry insider, “everyone is looking to AMD for cost reduction” – in other words, you don’t need to believe that the MI300 dominates the H100 in absolute terms to threaten Nvidia’s pricing power; you just need to undermine their price performance.
MosaicML has gotten AMD’s MI250s to work for training runs, but given the AMD software stack is distinct from Nvidia’s proprietary and dominant CUDA language, it will be hard to use the AMD stack in practice, unless OpenAI’s Triton or Modular can close the software support gap. In the world of a private cloud exec, “Who is going to take the risk of deploying 10,000 AMD GPUs or 10,000 silicon chips from a startup? That’s almost a $300 million investment.”
Startups
With $720m+ raised and a chip on the market, Cerebras is the most credible semiconductor startup. The architecture is radically different from Nvidia, with a 56x larger chip size to reduce the need for cross-GPU interconnect. While they seemingly have competitive performance to Nvidia, they’ll need to build developer trust to capture meaningful market share. Even if they can’t build commercial-scale production fast enough, the technology has immense M&A value for a second or third-place chip provider.
As for newer programs, it takes 5 years minimum from whiteboard to tapeout of a new chip. Even if AMD’s efforts go as planned, it’ll be 2025 at least before the Nvidia monopoly over GPU supply is broken. But the target on their back is only getting bigger, and while I think Nvidia ultimately retains its GPU dominance, its pricing power could get squeezed in the medium-term.
The post-Nvidia supply chain: is renting GPUs a good business?
Nvidia is unusual in that it typically doesn’t sell its products directly to end customers. After the GPU is designed and produced, there is a post-production supply chain of resellers and systems integrators:

If cloud providers have GPUs for rent, why do you need the upstarts? Hyperscalers like Azure, AWS, and GCP are only doling out GPUs at “reasonable” prices via long-term fixed contracts – e.g. AWS will rent you 8 H100s for 3 years for $1.1m (twice as much if you don’t reserve it up front!). Smaller companies have more sporadic demand and are looking for e.g. 1,000 GPUs for 1 month, then 200 GPUs for 3 months, then 500 GPUs for 5 months, etc.
Hyperscaler upstarts CoreWeave, Lambda, ML Foundry, and Together are working to plug that gap by providing easy, variable, rented (“serverless”) access to GPUs. These businesses had near-infinite demand this year, and very fast paybacks on their hardware setups. The businesses have a similar risk profile as the crypto miners from the last cycle: you’re necessarily making a levered bet on the GPU trade, in the same way that crypto miners made a levered bet on crypto.
On the demand side of the equation, there’s every reason to believe that demand for variable GPUs will sustain. If you're a small or medium-sized enterprise (say $0-100m raised) and want to train your own cutting-edge foundation model, you may need 5,000 Nvidia H100s – you can’t buy and install them yourself at $30k+ per device, and even if you could, you wouldn’t run them often enough to break even. It makes sense to use a third party reseller.
AWS announced a 20,000 H100 GPU cluster this summer, which should satisfy the needs of larger ML training runs once completed. And they’re taking advantage of the supply shortage, pricing to an implied 68% operating income margin. Long-term, though, AWS and Azure do not want to be GPU rental businesses – they want to be selling their broader services at high margins. In this sense, CoreWeave and Lambda can be durable as a Rackspace or DigitalOcean-style companies, if they can survive the volatility of supply and demand.
Nvidia rewards these resellers with high capacity and good pricing, since they’re not building competing chips like Microsoft and Google. This is a double-edged sword for Nvidia, since supporting the resellers gives the hyperscalers an even greater incentive to compete.
The resellers are benefitting from bringing highly sought after GPU supply online before anyone else did. Can they build durable businesses? The key axes of differentiation are scale, price performance, supply scalability, and the robustness of the software offering:
Scale: You need a critical scale for two key purposes: 1) to support larger language model training runs on cutting-edge models (e.g. 5,000+ 2020 vintage Nvidia A100s or cutting-edge H100s for weeks at a time, and 2) to keep utilization high across highly variable customer demand.
Price performance: If you view these companies as GPU-time resellers, then the supply cost really matters. Having preferential pricing as an Nvidia partner (i.e. getting the same pricing as Azure, AWS, et al) can save 30% of your cluster buildout cost. Players like Crusoe are lowering supply cost via cheaper energy. CoreWeave claims their A100s are 30% more price performant than A100s at a hyperscaler due to cluster architecture, virtualization methodology, cooling techniques, interconnect quality, etc. Some companies like Salad are even trying to aggregate cheaper supply by finding latent GPUs owned by consumers.
Supply scalability: Companies like Together and ML Foundry have “acquired” (rented) latent GPU supply from underutilized private clusters at mid-stage startups. While still in the technical research phase, synthetically aggregating GPU clusters could massively unlock the supply side of the GPU equation (similar to what Airbnb did for homes).
Software: Some companies are going “up the stack”, i.e. improving the developer experience on top of the GPUs. Modal, Lambda and RunPod each claim to provide a faster onboarding and smoother developer experience via software.
Given the primary revenue stream for these businesses is GPU-hours, they’re essentially a levered bet on GPU demand scaling, and a bet on the longevity of the H100 (if the GPUs become obsolete in 3 years, the depreciation hit will be painful). To make an investment in these companies, you need a strong directional view on medium-term GPU consumption scaling, or believe in the long-term leverage of building out a broader software suite.
Conclusion
A myriad of foundation model copycats resemble modern-day cargo cults. They are trying their best to reproduce the magic of the first wave of products, but don’t have all the required ingredients.
Given increased compute spend seems logarithmically tied to intelligence, it’s hard to envision a future where compute doesn’t grow exponentially. But unusually, the 20-year outlook is clearer to me than the 5-year. In the medium-term, the risk of overbuilding GPU clusters is high.
There are a few things worth watching to better understand the medium-term GPU outlook:
Large foundation model demand ramp: How much will OpenAI and other large-scale LLM providers ramp up GPU spend over the next 3-5 years? Many model providers are copying whatever OpenAI does, so their GPU consumption should be highly predictive of overall GPU demand growth. Most importantly, will the big GPU spenders ramp their cluster sizes faster than the long tail of demand withers?
Inference vs. training mix: Seeing a shift in GPU usage for inference would clarify whether the industry will remain H100-dependent over the coming years, or diversify to chips that are more inference-specific.
Price performance from alternatives: It’ll take years for others to catch up to the absolute performance of frontier Nvidia chips, but I would pay attention to the price performance of new semiconductor efforts. The bar here isn’t parity with Nvidia’s relatively low COGS, but with their retail price – this is when their pricing power could come under attack.
Publics
Nvidia’s exceptional growth comes with a curse of two challenging customer bases:
A concentrated set of buyers with strong incentives to develop competing chip programs.
A long tail of customers that are running speculative “build / fine-tune your own foundation model” experiments over the next year, where GPU demand predictability is impossible.
Given the cyclicality of GPU spend based on release timelines, and the valuation embedding indefinite exponential growth, I expect Nvidia to peak in the next 6-9 months, and cool off over a 2-3 year time horizon. I would change my mind if I see large H100 cluster scale-up plans from large foundation models, or high attach rates for upcoming AI product launches like Office Copilot.
I think buying AMD is a good way to bet on the long-term growth of GPUs without crowding into the Nvidia trade. They’ve lost the early race for accelerated compute, but there are lots of companies with multi-billion dollar incentives to see them succeed, and their upcoming MI chip series is promising. If anyone can chip away at Nvidia dominance, it’ll be AMD.
Don’t sue me if you lose money trading based off of my blog post (disclaimer: I’m long NVDA and AMD as of publishing).
Startups
There will be immense value in building software to reduce Nvidia dependence, particularly if it comes with clear improvements on price performance by leveraging other GPUs. If new ML frameworks like Modular can make workloads agnostic to the underlying GPU hardware, this would unlock cheaper supply, and change the cost-performance curve.
Be careful of investing into the GPU trade at the wrong time (and/or over-extending the risk of your “long GPU” trade), like investing in crypto mining rigs in 2021. In the last crypto cycle, there was big money to be made early in mining, until there was a supply glut and margins got crushed.
If AMD chips end up playing a meaningful role in the inference (deployment) phase of LLMs, there will be large new data centers built, given the current data centers focus on H100s / A100s, which are best for training. Inference-focused clusters may look radically different, requiring a mix of frontier Nvidia and AMD chips.
Thanks to Divyahans Gupta, Akshat Bubna, Melisa Tokmak Luttig, Harry Elliott, Philip Clark, Axel Ericsson, Cat Wu, Lachy Groom, David Cahn, Ben Gilbert, and Matt Kraning for their thoughts and feedback on this article.
This article is a masterpiece.
Always enjoy your posts, John. Very clear and thoughtful
Seems like their go forward growth targets are dependent on startups (more than 50% of H100 demand) building more foundation models. How feasible do you think that is given changing environment for AI funding?